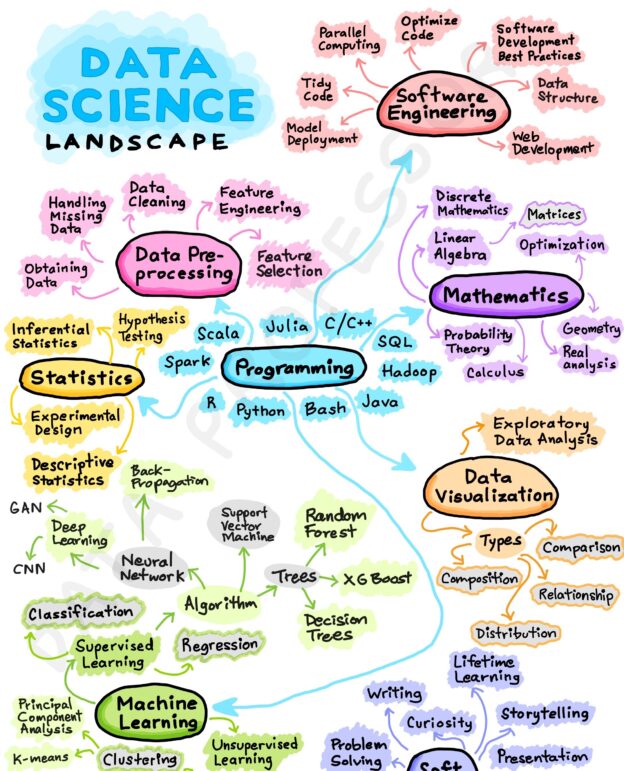
El camino para convertirse en un científico de datos puede variar dependiendo de las necesidades y objetivos individuales. A continuación, se presenta una posible hoja de ruta que puede seguir para convertirse en un científico de datos.
Aprender los fundamentos de las matemáticas y la estadística
Es importante tener una sólida comprensión de las matemáticas y la estadística para poder entender los conceptos fundamentales del análisis de datos. Esto incluye aprender sobre álgebra lineal, cálculo, probabilidad, estadística y análisis multivariado.
Álgebra lineal: El álgebra lineal es un área de las matemáticas que se centra en el estudio de vectores, matrices y sistemas de ecuaciones lineales. Es importante para la comprensión de muchos algoritmos y técnicas de Machine Learning utilizados en el análisis de datos.
Cálculo: El cálculo es un área de las matemáticas que se centra en el estudio de las funciones y sus propiedades. Es importante para la comprensión de muchas técnicas estadísticas y modelos de Machine Learning.
Probabilidad: La probabilidad es un área de las matemáticas que se centra en el estudio de eventos aleatorios y la probabilidad de que ocurran. Es fundamental para la comprensión de la estadística y la inferencia estadística utilizada en el análisis de datos.
Estadística: La estadística es el estudio de cómo recopilar, analizar e interpretar datos. Es importante para el análisis exploratorio de datos, la inferencia estadística y la validación de modelos.
Análisis multivariado: El análisis multivariado es un conjunto de técnicas estadísticas que se utilizan para analizar datos que tienen más de una variable independiente. Es importante para la exploración y visualización de datos, así como para la construcción de modelos predictivos complejos.
Es importante tener una sólida comprensión de estos conceptos matemáticos y estadísticos para poder aplicarlos de manera efectiva en el análisis de datos. Hay muchos recursos disponibles para aprender sobre matemáticas y estadísticas, como cursos en línea, libros de texto y tutoriales.
Aprender a programar
Aprender a programar es una habilidad fundamental para cualquier persona que quiera convertirse en un científico de datos. En particular, Python, R y SQL son lenguajes de programación ampliamente utilizados en la ciencia de datos.
Python es un lenguaje de programación de propósito general que es fácil de aprender y usar. Tiene una amplia variedad de bibliotecas para la ciencia de datos, como NumPy, Pandas, Matplotlib, Scikit-learn y TensorFlow. Aprender a programar en Python es una habilidad esencial para cualquier persona que quiera trabajar en la ciencia de datos.
R es otro lenguaje de programación popular para la ciencia de datos. Es conocido por sus capacidades estadísticas y su capacidad para producir gráficos de alta calidad. R es utilizado por muchos científicos de datos para la exploración y visualización de datos, así como para el análisis estadístico.
SQL, por otro lado, es un lenguaje de consulta utilizado para interactuar con bases de datos relacionales. Es esencial para cualquier persona que quiera trabajar con grandes conjuntos de datos almacenados en bases de datos. Aprender SQL es una habilidad importante para cualquier persona que quiera trabajar en la ciencia de datos.
Aprender a programar en Python, R o SQL puede ser una tarea desafiante, pero hay muchas opciones de formación disponibles para ayudar en este proceso. Hay muchos cursos en línea, tutoriales y libros que se enfocan específicamente en enseñar estos lenguajes de programación y cómo aplicarlos en la ciencia de datos. Es importante invertir tiempo y esfuerzo en el aprendizaje de estos lenguajes de programación, ya que son habilidades esenciales para cualquier persona que quiera trabajar en la ciencia de datos.
Machine Learning
Aprender machine learning es una habilidad fundamental para ser un científico de datos. El aprendizaje automático se utiliza para construir modelos que permiten tomar decisiones, predecir resultados y clasificar datos en una amplia variedad de situaciones. A través del aprendizaje automático, se pueden extraer patrones, relaciones y tendencias a partir de grandes conjuntos de datos.
Además, es importante comprender las técnicas de validación de modelos, tales como la validación cruzada, y la selección de modelos, y cómo evaluar la calidad de los modelos. También es importante tener conocimiento sobre los algoritmos de machine learning supervisados y no supervisados, y sobre cómo seleccionar y ajustar los parámetros de estos algoritmos para obtener mejores resultados.
Aprender sobre bases de datos y tecnologías de almacenamiento de datos
Para convertirse en un científico de datos competente, es fundamental tener una comprensión sólida de las bases de datos y las tecnologías de almacenamiento de datos. Los datos son la base de la ciencia de datos y se almacenan en bases de datos y sistemas de almacenamiento de datos.
Es importante conocer los diferentes tipos de bases de datos, como las bases de datos relacionales y no relacionales. Las bases de datos relacionales son las más comunes y utilizan tablas para almacenar los datos. SQL es el lenguaje utilizado para interactuar con bases de datos relacionales. Por otro lado, las bases de datos no relacionales, como MongoDB y Cassandra, no utilizan tablas y en su lugar usan estructuras de datos como documentos o gráficos para almacenar los datos.
También es importante conocer las tecnologías de almacenamiento de datos, como los sistemas de archivos distribuidos y los sistemas de almacenamiento en la nube. Los sistemas de archivos distribuidos, como Hadoop, se utilizan para procesar grandes cantidades de datos en paralelo en un clúster de servidores. Los sistemas de almacenamiento en la nube, como Amazon S3 y Google Cloud Storage, permiten a las empresas almacenar grandes cantidades de datos en la nube de manera segura y escalable.
Hay muchas opciones de formación disponibles para aprender sobre bases de datos y tecnologías de almacenamiento de datos. Los cursos en línea, los libros y los tutoriales son excelentes recursos para obtener una comprensión sólida de estas tecnologías. Además, muchos proveedores de tecnología ofrecen cursos de capacitación y certificaciones para sus productos, lo que puede ser una excelente manera de adquirir habilidades prácticas en bases de datos y tecnologías de almacenamiento de datos.
Aprender sobre herramientas y tecnologías de análisis de datos
Para convertirse en un científico de datos competente, es esencial conocer las herramientas y tecnologías de análisis de datos. Las herramientas y tecnologías de análisis de datos se utilizan para realizar análisis estadísticos, modelado y visualización de datos.
Algunas de las herramientas y tecnologías de análisis de datos más populares incluyen:
Excel
Una herramienta ampliamente utilizada para el análisis de datos y la visualización de datos.
Tableau
Tableau es una herramienta de visualización de datos que permite a los usuarios crear paneles interactivos y gráficos. Es ampliamente utilizada en la ciencia de datos y el análisis empresarial debido a su facilidad de uso y su capacidad para crear visualizaciones altamente interactivas y atractivas.
Algunas de las características y beneficios clave de Tableau incluyen:
Conexión a una amplia variedad de fuentes de datos: Tableau puede conectarse a una amplia variedad de fuentes de datos, incluyendo bases de datos relacionales, bases de datos NoSQL, archivos de Excel, archivos CSV y más.
Creación de visualizaciones de datos altamente interactivas: Tableau permite a los usuarios crear visualizaciones altamente interactivas, lo que significa que los usuarios pueden explorar y analizar los datos en tiempo real.
Creación de paneles de control personalizados: Tableau permite a los usuarios crear paneles de control personalizados para visualizar y analizar datos en un formato fácil de usar.
Integración con otras herramientas y tecnologías de análisis de datos: Tableau se integra con otras herramientas y tecnologías de análisis de datos, lo que permite a los usuarios realizar análisis estadísticos avanzados y modelado de datos.
Facilidad de uso: Tableau es fácil de usar y no requiere habilidades de programación avanzadas, lo que significa que los usuarios pueden comenzar a crear visualizaciones y paneles de control rápidamente.
Power BI
Permite a los usuarios crear visualizaciones y paneles de control interactivos y dinámicos. Es una herramienta popular entre los profesionales de análisis de datos debido a su capacidad para conectarse a múltiples fuentes de datos y su integración con otras herramientas de Microsoft.
Algunas de las características y beneficios clave de Power BI incluyen:
Conexión a múltiples fuentes de datos: Power BI puede conectarse a una amplia variedad de fuentes de datos, incluyendo bases de datos relacionales, bases de datos NoSQL, archivos de Excel, archivos CSV y más.
Creación de visualizaciones de datos interactivas: Power BI permite a los usuarios crear visualizaciones altamente interactivas y dinámicas que se actualizan en tiempo real.
Integración con otras herramientas de Microsoft: Se integra con otras herramientas de Microsoft, como Excel, SharePoint y Dynamics 365, lo que permite a los usuarios analizar datos de múltiples fuentes.
Acceso móvil y en la nube: Está disponible en la nube y en dispositivos móviles, lo que permite a los usuarios acceder a los datos y las visualizaciones desde cualquier lugar.
Seguridad y control: Power BI ofrece funciones de seguridad y control, lo que permite a los administradores de TI controlar el acceso a los datos y las visualizaciones.
RStudio
Un entorno de desarrollo integrado para el lenguaje de programación R, que se utiliza ampliamente en la ciencia de datos.
Jupyter Notebook
Una plataforma web que permite a los usuarios crear y compartir documentos que contienen código, visualizaciones y texto.
Aprender a usar estas herramientas y tecnologías de análisis de datos es fundamental para cualquier persona que quiera trabajar en la ciencia de datos. Hay muchas opciones de formación disponibles para aprender sobre estas herramientas y tecnologías, incluyendo cursos en línea, tutoriales y libros. Además, muchas empresas ofrecen capacitación y certificaciones para sus herramientas y tecnologías de análisis de datos, lo que puede ser una excelente manera de adquirir habilidades prácticas en esta área.
Aprender sobre la comunicación de datos y visualización
Aprender sobre la comunicación de datos y visualización es fundamental para cualquier científico de datos. Los datos no tienen ningún valor si no se pueden comunicar de manera efectiva a los usuarios finales. La visualización de datos es una forma poderosa de comunicar información de manera clara y efectiva, lo que puede mejorar la toma de decisiones y la comprensión de los datos.
Algunas de las técnicas y herramientas clave que se deben aprender para comunicar datos y visualización incluyen:
Diseño visual: Aprender los principios del diseño visual es importante para crear visualizaciones de datos atractivas y efectivas. Esto incluye el uso de colores, tipografía, diseño de gráficos y más.
Gráficos y visualizaciones: Aprender a crear y utilizar diferentes tipos de gráficos y visualizaciones, como gráficos de barras, gráficos circulares, gráficos de líneas, mapas y más. Es importante conocer cuándo y cómo utilizar cada tipo de visualización para comunicar de manera efectiva los datos.
Comunicación efectiva: Además de aprender las habilidades técnicas de visualización de datos, también es importante aprender cómo comunicar de manera efectiva la información a los usuarios finales. Esto incluye saber cómo presentar la información de manera clara y concisa, cómo adaptarse a la audiencia y cómo utilizar ejemplos y analogías para mejorar la comprensión.
Hay muchos recursos disponibles para aprender sobre la comunicación de datos y visualización, incluyendo cursos en línea, tutoriales, libros y más. También hay comunidades en línea, como Reddit y Stack Overflow, donde los profesionales pueden hacer preguntas y compartir recursos.
Participar en proyectos de análisis de datos
Participar en proyectos de análisis de datos es una forma valiosa de adquirir experiencia práctica y desarrollar habilidades en el mundo real. Los proyectos de análisis de datos pueden tomar muchas formas, desde proyectos personales hasta proyectos de grupo en empresas y organizaciones.
Algunos beneficios de participar en proyectos de análisis de datos incluyen:
Desarrollo de habilidades: Al trabajar en proyectos de análisis de datos, se tiene la oportunidad de desarrollar habilidades en áreas como la limpieza y preparación de datos, modelado y análisis estadístico, visualización de datos y más.
Experiencia práctica: La experiencia práctica en proyectos de análisis de datos es valiosa para demostrar las habilidades a los empleadores potenciales y para aplicarlas a situaciones en el mundo real.
Colaboración: Los proyectos de análisis de datos pueden involucrar trabajar en equipo, lo que puede ayudar a desarrollar habilidades de colaboración y comunicación.
Ampliar el portafolio: Los proyectos de análisis de datos pueden ser agregados al portafolio, lo que puede ayudar a destacar las habilidades y proyectos relevantes para los empleadores potenciales.
Para participar en proyectos de análisis de datos, se pueden buscar oportunidades en línea, como sitios web de freelancing, proyectos de código abierto en GitHub, o incluso proyectos internos en la empresa. También se pueden crear proyectos personales utilizando conjuntos de datos públicos o privados.
Al participar en proyectos de análisis de datos, es importante seguir las mejores prácticas de la industria, como documentar los procesos y los resultados, utilizar técnicas de limpieza y preparación de datos eficientes y efectivas, y asegurarse de que la visualización y comunicación de los resultados sean claras y precisas.