Las métricas de evaluación son medidas utilizadas para evaluar el rendimiento de los modelos de aprendizaje automático. Estas métricas se utilizan para comparar diferentes modelos y seleccionar el que tenga un mejor rendimiento en base a las necesidades y objetivos del problema a resolver.
Existen diferentes métricas de evaluación que se utilizan según el tipo de problema de aprendizaje automático. Por ejemplo, para problemas de clasificación se utilizan métricas como Exactitud, Precisión, Sensibilidad, F1 score y AUC-ROC, mientras que para problemas de regresión se utilizan métricas como MAE, MSE, RMSE y R2.
Es importante seleccionar la métrica de evaluación adecuada según el problema a resolver, ya que cada métrica tiene una interpretación diferente y puede ser más apropiada según los objetivos del proyecto. Además, es importante tener en cuenta que una buena métrica de evaluación debe ser consistente con el objetivo del problema y reflejar de manera precisa el rendimiento del modelo en la tarea a resolver.
Índice
TogglePara algoritmos de Clasificación generalmente se utilizan las siguientes métricas:
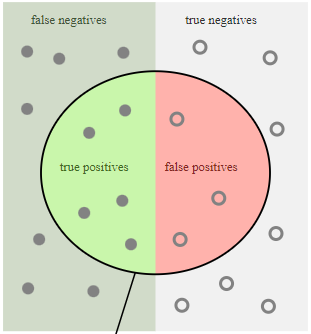
Matriz de Confusión
Es una herramienta utilizada en problemas de clasificación para evaluar el rendimiento de un modelo de aprendizaje automático. La matriz de confusión muestra la cantidad de casos que el modelo ha clasificado correctamente e incorrectamente en cada clase.
La matriz de confusión es una matriz cuadrada con el número de filas y columnas igual al número de clases en el problema de clasificación. En una matriz de confusión binaria, como la que se utiliza en un problema de clasificación con dos clases, la matriz tiene la siguiente forma:
| Predicción Positiva | Predicción NEGATIVa | |
|---|---|---|
| Real positivo | Verdaderos positivos (TP) | Falsos negativos (FP) |
| Real negativo | Falsos positivos (FN) | Verdaderos negativos (TN) |
Donde:
- Verdaderos positivos (TP, True Positives): número de casos positivos que el modelo ha clasificado correctamente.
- Falsos positivos (FP, False Positives): número de casos negativos que el modelo ha clasificado incorrectamente como positivos.
- Verdaderos negativos (TN, True Negatives): número de casos negativos que el modelo ha clasificado correctamente.
- Falsos negativos (FN, False Negatives): número de casos positivos que el modelo ha clasificado incorrectamente como negativos.
La matriz de confusión se utiliza para calcular varias métricas de evaluación del modelo, como la precisión, la sensibilidad y la especificidad. También se puede utilizar para visualizar el rendimiento del modelo en diferentes clases y para identificar patrones de error en la clasificación.
Es importante tener en cuenta que la matriz de confusión depende del umbral de decisión utilizado para clasificar los casos en cada clase. Por lo tanto, es importante ajustar el umbral de decisión según los objetivos del problema de clasificación y las necesidades específicas de la aplicación.
Exactitud
La exactitud (accuracy en inglés) es una métrica de evaluación utilizada en problemas de clasificación que mide la proporción de casos clasificados correctamente por el modelo. Es decir, la exactitud es la proporción de casos clasificados correctamente sobre el total de casos.
La fórmula para calcular la exactitud es la siguiente:
Exactitud = (Verdaderos positivos + Verdaderos negativos) / Total de casos
Donde:
- Verdaderos positivos (TP, True Positives): número de casos positivos que el modelo ha clasificado correctamente.
- Verdaderos negativos (TN, True Negatives): número de casos negativos que el modelo ha clasificado correctamente.
- Total de casos: número total de casos en el conjunto de datos.
La exactitud proporciona una medida del rendimiento global del modelo en la tarea de clasificación. Una exactitud alta indica que el modelo ha clasificado la mayoría de los casos correctamente, mientras que una exactitud baja indica que el modelo ha cometido errores en la clasificación.
Sin embargo, es importante tener en cuenta que la exactitud puede ser engañosa en algunos casos, especialmente cuando los datos están desequilibrados y hay una clase minoritaria. En estos casos, un modelo que siempre predice la clase mayoritaria puede tener una alta exactitud pero no ser útil en la práctica. Por lo tanto, es importante utilizar otras métricas de evaluación en conjunto con la exactitud para tener una visión más completa del rendimiento del modelo en la tarea de clasificación.
Precisión
La precisión (precision en inglés) es una métrica de evaluación utilizada en problemas de clasificación que mide la proporción de casos positivos identificados correctamente por el modelo sobre el total de casos identificados como positivos.
La fórmula para calcular la precisión es la siguiente:
Precisión = Verdaderos positivos / (Verdaderos positivos + Falsos positivos)
Donde:
- Verdaderos positivos (TP, True Positives): número de casos positivos que el modelo ha clasificado correctamente.
- Falsos positivos (FP, False Positives): número de casos negativos que el modelo ha clasificado incorrectamente como positivos.
La precisión es importante cuando el costo de un falso positivo es alto, es decir, cuando es importante minimizar los casos en que se clasifica incorrectamente un caso negativo como positivo. Por ejemplo, en un problema de detección de spam en el correo electrónico, es importante minimizar los casos en que un correo electrónico legítimo es clasificado como spam.
Sin embargo, la precisión no considera los casos que el modelo no ha identificado correctamente como positivos, es decir, los falsos negativos (FN, False Negatives). Por lo tanto, es importante utilizar otras métricas de evaluación en conjunto con la precisión para tener una visión más completa del rendimiento del modelo en la tarea de clasificación.
Sensibilidad
La sensibilidad (recall en inglés) es una métrica de evaluación utilizada en problemas de clasificación que mide la proporción de casos positivos identificados correctamente por el modelo sobre el total de casos positivos presentes en los datos.
La fórmula para calcular la sensibilidad es la siguiente:
Sensibilidad = Verdaderos positivos / (Verdaderos positivos + Falsos negativos)
Donde:
- Verdaderos positivos (TP, True Positives): número de casos positivos que el modelo ha clasificado correctamente.
- Falsos negativos (FN, False Negatives): número de casos positivos que el modelo ha clasificado incorrectamente como negativos.
La sensibilidad es importante cuando el costo de un falso negativo es alto, es decir, cuando es importante identificar correctamente todos los casos positivos presentes en los datos. Por ejemplo, en un problema de diagnóstico médico, es importante identificar correctamente todos los casos de una enfermedad para poder proporcionar el tratamiento adecuado.
La sensibilidad no considera los casos que el modelo ha identificado incorrectamente como positivos, es decir, los falsos positivos (FP, False Positives). Por lo tanto, es importante utilizar otras métricas de evaluación en conjunto con la sensibilidad para tener una visión más completa del rendimiento del modelo en la tarea de clasificación.
F1 Score
El F1 Score es una métrica de evaluación utilizada comúnmente en problemas de clasificación que combina la precisión (precision) y la sensibilidad (recall) en una sola medida. Esta métrica proporciona una forma de evaluar la precisión y el rendimiento del modelo en una tarea de clasificación binaria.
El F1 Score se calcula como la media armónica de la precisión y la sensibilidad, y se utiliza para encontrar un equilibrio entre ambas métricas. La fórmula para calcular el F1 Score es la siguiente:
F1 Score = 2 * (precision * recall) / (precision + recall)
Donde:
- Precision: Proporción de casos positivos correctamente identificados entre el total de casos identificados como positivos.
- Recall: Proporción de casos positivos correctamente identificados entre el total de casos positivos presentes en los datos.
El valor del F1 Score oscila entre 0 y 1, siendo 1 el mejor valor posible. Un F1 Score alto indica que el modelo tiene un buen equilibrio entre precisión y sensibilidad, lo que significa que es capaz de identificar correctamente tanto los casos positivos como los negativos.
El F1 Score es especialmente útil cuando los datos están desequilibrados y hay más casos negativos que positivos o viceversa. En estos casos, la precisión y la sensibilidad por separado pueden ser engañosas, y el F1 Score proporciona una medida más precisa del rendimiento del modelo en la tarea de clasificación.
AUC – ROC
La métrica de evaluación AUC-ROC (área bajo la curva ROC) es una medida de la calidad de la predicción en problemas de clasificación binaria. ROC significa Receiver Operating Characteristic, y la curva ROC representa la tasa de verdaderos positivos (sensibilidad) frente a la tasa de falsos positivos (1 – especificidad) para diferentes valores de umbral de decisión.
El área bajo la curva ROC (AUC-ROC) es una medida de la capacidad de discriminación del modelo, es decir, su capacidad para distinguir entre casos positivos y negativos. Un valor de AUC-ROC de 1 indica una capacidad perfecta para distinguir entre casos positivos y negativos, mientras que un valor de 0,5 indica que el modelo no es mejor que una elección aleatoria.
La AUC-ROC se puede interpretar como la probabilidad de que el modelo clasifique un ejemplo positivo aleatorio con mayor puntuación que un ejemplo negativo aleatorio. Por lo tanto, cuanto mayor sea el valor de AUC-ROC, mejor será el rendimiento del modelo en la tarea de clasificación binaria.
Es importante tener en cuenta que la AUC-ROC no se ve afectada por cambios en la distribución de clases o en la escala de los valores de predicción. Por lo tanto, es una métrica de evaluación útil cuando se trabaja con conjuntos de datos desequilibrados o cuando la interpretación de los valores de predicción es difícil. Sin embargo, la AUC-ROC no proporciona información detallada sobre el rendimiento del modelo para diferentes valores de umbral de decisión, por lo que es importante utilizar otras métricas de evaluación en conjunto con la AUC-ROC para tener una visión más completa del rendimiento del modelo en la tarea de clasificación binaria.
Para algoritmos de Regresión generalmente se utilizan las siguientes métricas:
Error Absoluto Medio (MAE)
MAE, del inglés Mean Absolute Error (Error Absoluto Medio), es una métrica comúnmente utilizada para evaluar el rendimiento de un modelo de regresión. El MAE mide la diferencia media absoluta entre las predicciones del modelo y los valores reales.
La fórmula del MAE es la siguiente:
MAE = (1/n) * Σ|y_pred – y_true|
Donde:
- y_pred: valor predicho por el modelo.
- y_true: valor real de la variable de respuesta.
- n: número de observaciones.
El MAE se calcula sumando las diferencias absolutas entre las predicciones del modelo y los valores reales para cada observación y luego dividiendo por el número de observaciones.
El MAE es una métrica de error en la misma unidad que la variable de respuesta, lo que significa que se puede interpretar directamente el tamaño promedio del error. Un MAE de 0 indica que el modelo predice exactamente los valores reales, mientras que un MAE mayor indica que el modelo tiene un mayor error promedio.
El MAE es útil cuando se desea evaluar el rendimiento del modelo en términos de la magnitud del error y no se desea penalizar en exceso los valores atípicos (outliers) o errores extremos. Sin embargo, puede ser sensible a los valores atípicos y no tener en cuenta la dirección de los errores. Por lo tanto, se recomienda utilizar el MAE junto con otras métricas para tener una evaluación más completa del modelo.
Error Cuadrático Medio (MSE)
MSE, del inglés Mean Squared Error (Error Cuadrático Medio), es otra métrica comúnmente utilizada para evaluar el rendimiento de un modelo de regresión. El MSE mide el promedio de las diferencias al cuadrado entre las predicciones del modelo y los valores reales.
La fórmula del MSE es la siguiente:
MSE = (1/n) * Σ(y_pred – y_true)^2
Donde:
- y_pred: valor predicho por el modelo.
- y_true: valor real de la variable de respuesta.
- n: número de observaciones.
El MSE se calcula sumando las diferencias al cuadrado entre las predicciones del modelo y los valores reales para cada observación y luego dividiendo por el número de observaciones.
También es una métrica de error en la misma unidad que la variable de respuesta, lo que significa que se puede interpretar directamente el tamaño promedio del error. Sin embargo, al elevar al cuadrado las diferencias, el MSE penaliza más los errores grandes que los pequeños, lo que puede ser deseable en algunos casos, como cuando los errores grandes son más costosos.
El MSE es útil cuando se desea evaluar el rendimiento del modelo en términos de la magnitud del error y se desea penalizar más los errores grandes que los pequeños. Sin embargo, al igual que el MAE, puede ser sensible a los valores atípicos y no tener en cuenta la dirección de los errores. Por lo tanto, se recomienda utilizar el MSE junto con otras métricas para tener una evaluación más completa del modelo.
Raíz del Error Cuadrático Medio (RMSE)
RMSE, del inglés Root Mean Squared Error (Raíz del Error Cuadrático Medio), es una métrica comúnmente utilizada para evaluar el rendimiento de un modelo de regresión. El RMSE mide la raíz cuadrada del promedio de las diferencias al cuadrado entre las predicciones del modelo y los valores reales.
La fórmula del RMSE es la siguiente:
RMSE = √(MSE)
Donde MSE es el Mean Squared Error, que se calcula como se indicó anteriormente.
El RMSE también es una métrica de error en la misma unidad que la variable de respuesta, lo que significa que se puede interpretar directamente el tamaño promedio del error. Al calcular la raíz cuadrada del MSE, el RMSE tiene la misma unidad que la variable de respuesta original.
El RMSE se utiliza comúnmente para comparar el rendimiento de diferentes modelos de regresión, ya que proporciona una medida de la magnitud del error que es fácil de interpretar y comparar entre modelos. Al igual que el MSE, el RMSE penaliza más los errores grandes que los pequeños, lo que puede ser deseable en algunos casos.
Al igual que el MAE y el MSE, el RMSE puede ser sensible a los valores atípicos y no tener en cuenta la dirección de los errores. Por lo tanto, se recomienda utilizar el RMSE junto con otras métricas para tener una evaluación más completa del modelo.
R2
El coeficiente de determinación, también conocido como R2, es una métrica utilizada comúnmente para evaluar el rendimiento de un modelo de regresión. El R2 mide la proporción de la varianza total de la variable de respuesta que es explicada por el modelo.
El R2 varía de 0 a 1, donde 0 indica que el modelo no explica la variabilidad de la variable de respuesta y 1 indica que el modelo explica toda la variabilidad de la variable de respuesta. Un R2 cercano a 1 indica que el modelo ajusta bien los datos.
La fórmula del R2 es la siguiente:
R2 = 1 – (SSres / SStot)
Donde:
- SSres: Suma de los cuadrados de los residuos (suma de los cuadrados de las diferencias entre las predicciones del modelo y los valores reales).
- SStot: Suma total de los cuadrados (suma de los cuadrados de las diferencias entre los valores reales y la media de los valores reales).
El R2 se puede interpretar como la proporción de la variabilidad total en la variable de respuesta que es explicada por el modelo. Un R2 cercano a 1 indica que el modelo ajusta bien los datos, mientras que un R2 cercano a 0 indica que el modelo no explica bien la variabilidad en la variable de respuesta.
El R2 es una métrica útil para evaluar el rendimiento del modelo en términos de la varianza explicada, pero no tiene en cuenta la dirección de los errores y puede ser sensible a los valores atípicos. Por lo tanto, se recomienda utilizar el R2 junto con otras métricas para tener una evaluación más completa del modelo.
En resumen, existen diferentes métricas de evaluación en machine learning que se utilizan para medir el rendimiento de un modelo. Cada métrica proporciona información útil sobre el desempeño del modelo y se utiliza en diferentes contextos según el problema a resolver.
Es importante tener en cuenta que ninguna métrica es perfecta y cada una tiene sus limitaciones. Por lo tanto, es recomendable utilizar varias métricas para tener una evaluación más completa del modelo y tomar decisiones informadas sobre su rendimiento.